

Check out this talk recorded at OpenSearchCon 2023, or continue reading.
Most custom functionality in OpenSearch is implemented with plugins. That is, in theory. In practice, much of core functionality is also implemented in plugins. For example, security or k-NN search are both plugins, even though one would reasonably expect a security framework to be part of the core engine (with multiple implementations in plugins), or for k-NN search to be living right next to full text search. Furthermore, some plugins, such repository-s3 that reads and writes snapshots from/to Amazon S3, live in core, whereas one would expect optional functionality to be … optional. The location for plugins is more a consequence of business and organizational decisions than technical. Software architecture really tends to line up to our business structures!
The default distribution of OpenSearch 2.10 ships with 20 plugins, all enabled by default, erasing much of the difference between what’s core vs. what’s a plugin. A vast majority of users install and run the whole thing.
Plugins suffer from 3 major limitations: rigid version compatibility, lack of isolation, and transitive dependency hell. These problems are described in great detail in this blog post, but before we go there, let’s follow another blog post and write a plugin that implements a RESTful API. The complete source code for the plugin is here.
A plugin inherits from Plugin and our plugin implements ActionPlugin (a plugin that exposes actions via REST). Our REST handler responds to GET requests.
public class HelloPlugin extends Plugin implements ActionPlugin {
@Override
public List getRestHandlers(final Settings settings,
final RestController restController,
final ClusterSettings clusterSettings,
final IndexScopedSettings indexScopedSettings,
final SettingsFilter settingsFilter,
final IndexNameExpressionResolver indexNameExpressionResolver,
final Supplier nodesInCluster) {
return singletonList(new RestHelloAction());
}
}
public class RestHelloAction extends BaseRestHandler {
@Override
public List routes() {
return unmodifiableList(asList(
new Route(GET, "/_plugins/hello-world-java")
));
}
@Override
protected RestChannelConsumer prepareRequest(
RestRequest request,
NodeClient client) throws IOException {
return channel -> {
channel.sendResponse(new BytesRestResponse(
RestStatus.OK,
"Hello from Java! 👋\n"
)
);
}
}
Let’s install the plugin, start OpenSearch, and make an HTTP request to the newly added endpoint on the OpenSearch node. The request will be forwarded to the plugin and the REST handler will handle it.
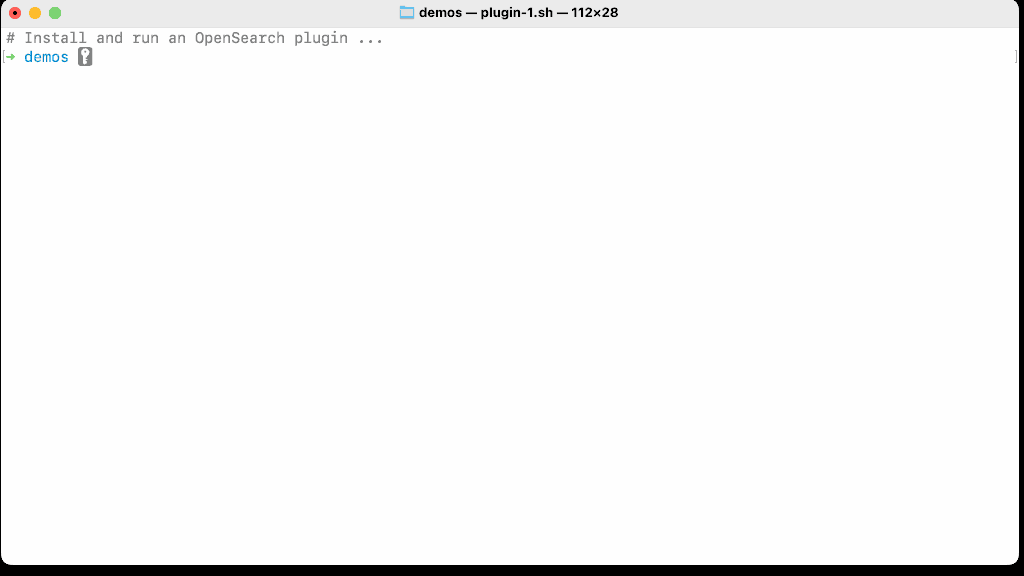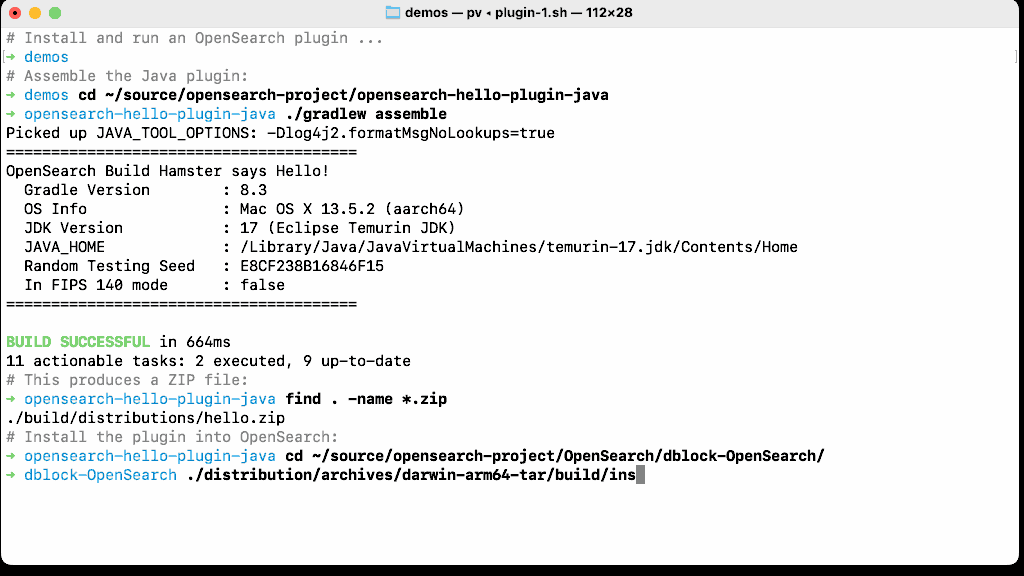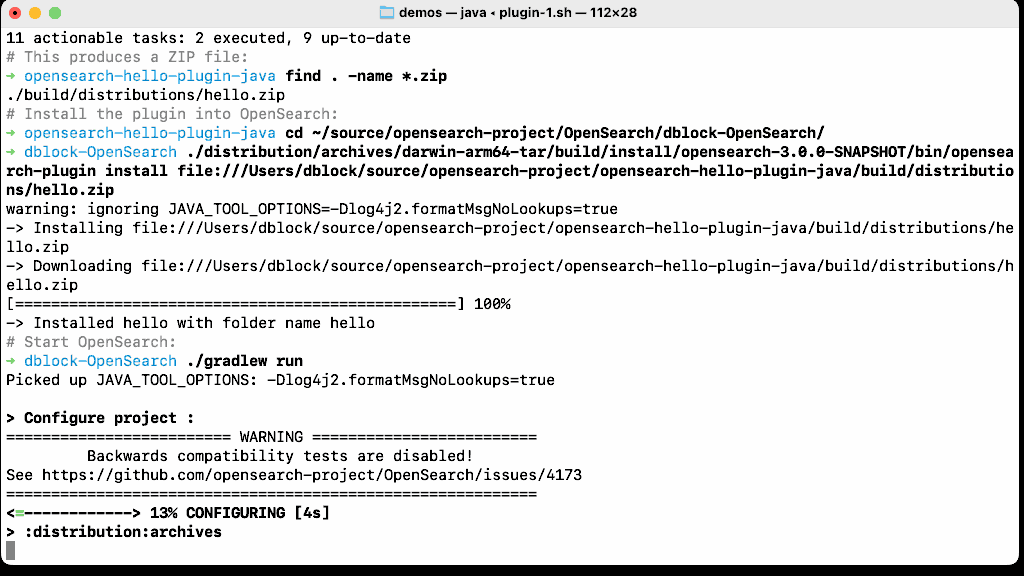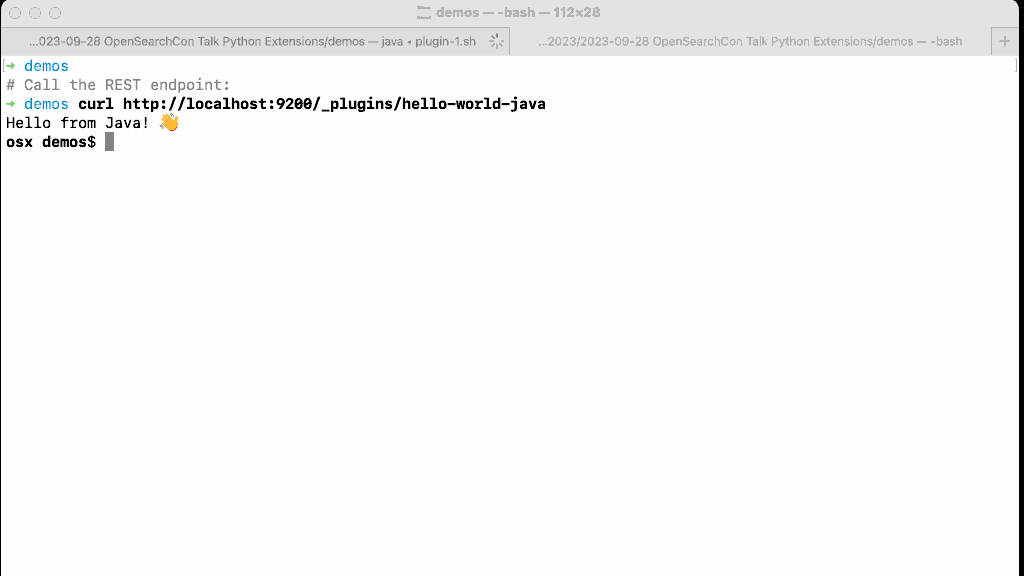
How easy was it to write a plugin? Very easy! But it’s much harder to write a production plugin on top of a 1.4MM LOC OpenSearch core. You will need to master dependency injection, understand OpenSearch runtime thread pools, and the (optional) security framework. Finally, I promise that you will have a very hard time playing nice with other plugins that share the same Java heap, and execute in the same Java Virtual Machine, deployed on every node in a large scale cluster that is actively indexing petabytes of data, or serving thousands of searches per second.
What can we do to help it?
In OpenSearch 2.9 we have introduced a new concept called extensions and shipped an experimental OpenSearch Java SDK. Extensions are full processes, run on a separate JVM and can execute on a separate host.
The code for an extension with its REST handler is almost identical to the one for a plugin. This was done on purpose to help migrations. The complete source code for this extension is here.
public class HelloWorldExtension extends BaseExtension implements ActionExtension {
@Override
public List<ExtensionRestHandler> getExtensionRestHandlers() {
return List.of(new RestHelloAction());
);
}
public class RestHelloAction extends BaseExtensionRestHandler {
@Override
public List<NamedRoute> routes() {
return List.of(
new NamedRoute.Builder().method(GET).path("/hello")
.handler(handleGetRequest)
.build();
)
}
private Function<RestRequest, ExtensionRestResponse> handleGetRequest =
(request) -> {
return new ExtensionRestResponse(
request, OK, "Hello from Java! 👋\n"
);
}
}
Let’s enable the experimental extensions feature in OpenSearch, install and run this extension.
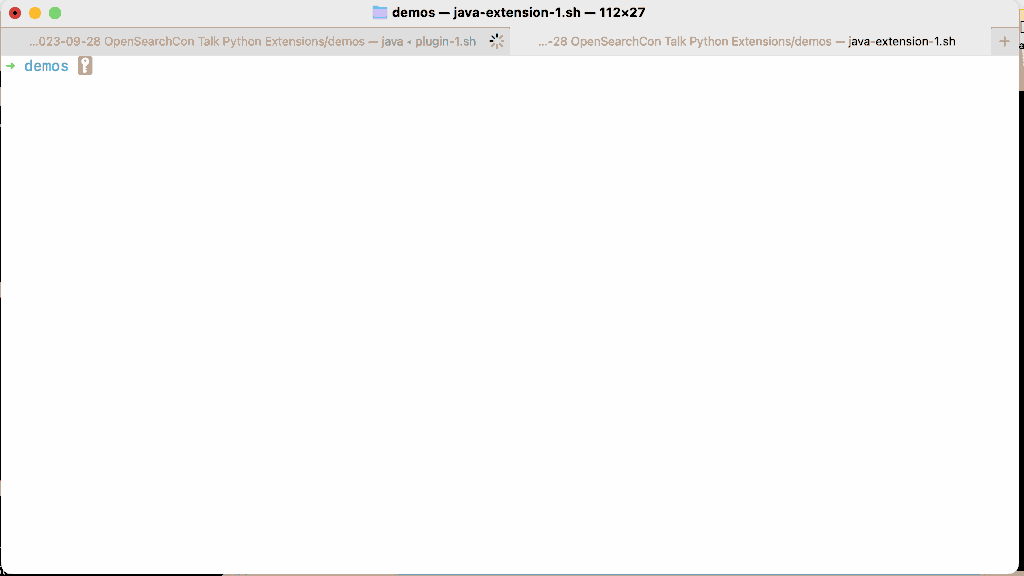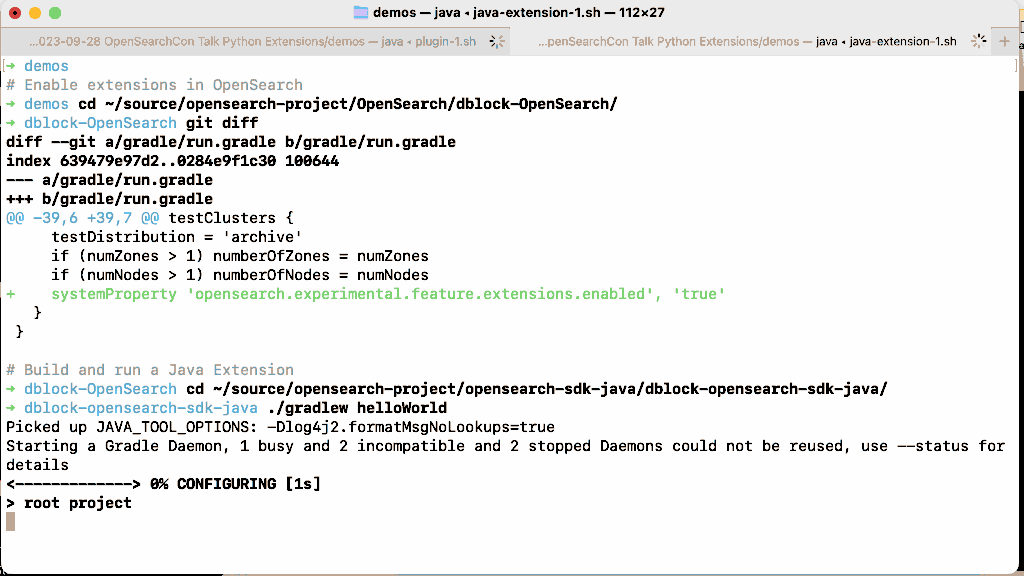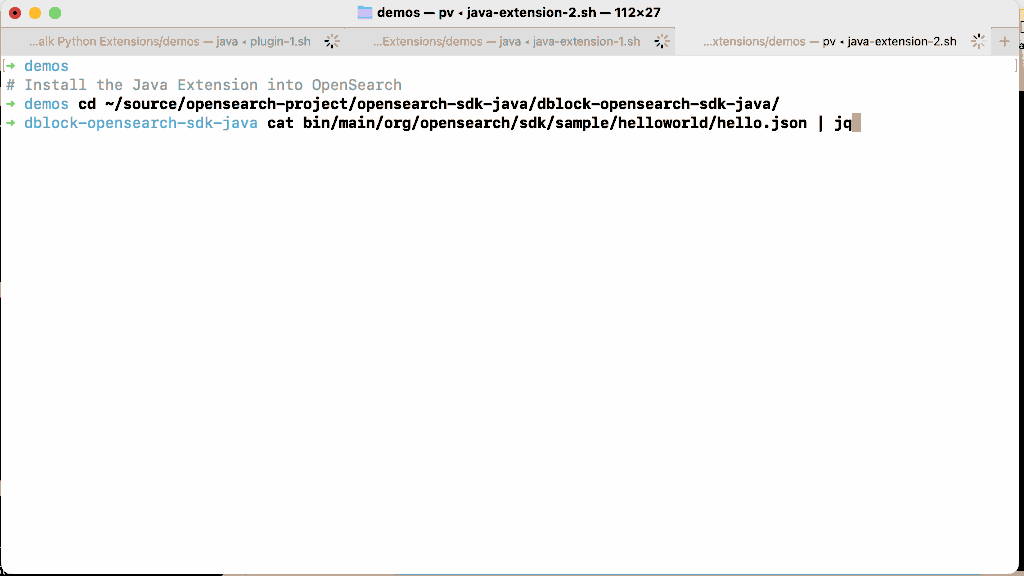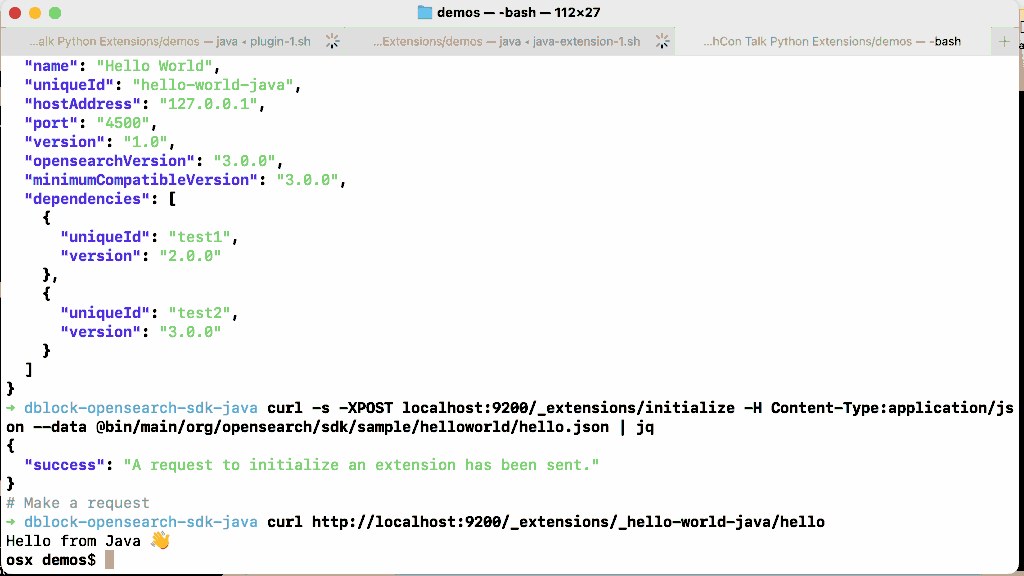
Extensions overcome the major limitations of plugins by being semver compatible (you can run an extension on many versions of OpenSearch without rebuilding it), do not require restarting a cluster to be installed, and are isolated at runtime. Because you can run an extension remotely, you can also right-size the extension node (no need to add memory to every node in the cluster because one plugin occasionally needs it). In the introductory blog post we cut the cost of a 36-node cluster that performed high cardinality anomaly detection by a third using extensions.
Other than reducing costs, what else can we use this technology for?
Python is the language of machine learning. Unlike a plugin, we can also write an extension in Python. The complete source code for the sample below is here and it looks very similar to the Java one.
class HelloExtension(Extension, ActionExtension):
def __init__(self):
Extension.__init__(self, "hello-world")
ActionExtension.__init__(self)
@property
def rest_handlers(self):
return [HelloRestHandler()]
class HelloRestHandler(ExtensionRestHandler):
def handle_request(self, rest_request):
return ExtensionRestResponse(
RestStatus.OK,
bytes("Hello from Python! 👋\n"),
ExtensionRestResponse.TEXT_CONTENT_TYPE
)
@property
def routes(self):
return [
NamedRoute(method=RestMethod.GET, path="/hello")
]
Let’s enable the experimental extensions feature in OpenSearch, install and run this extension.
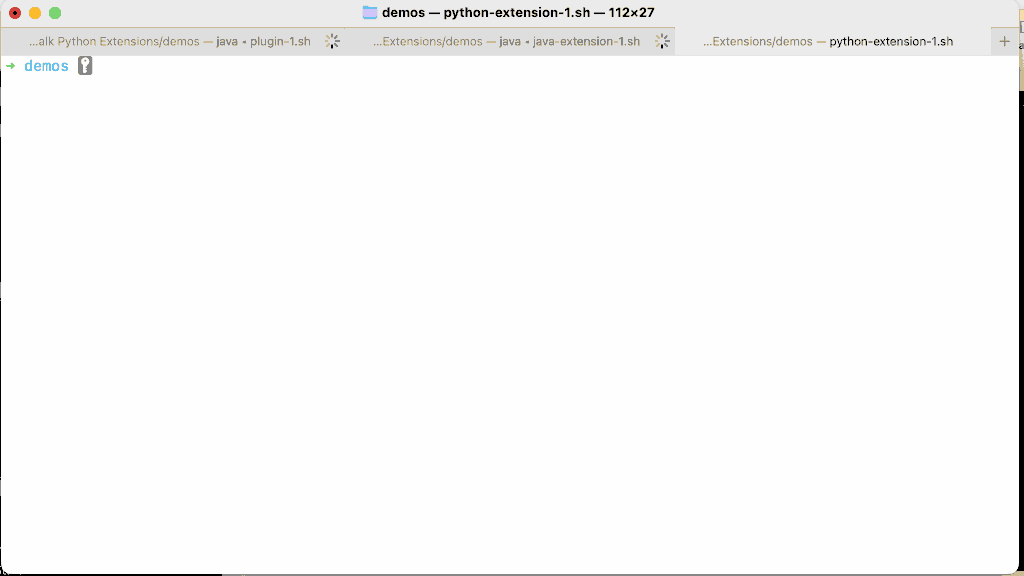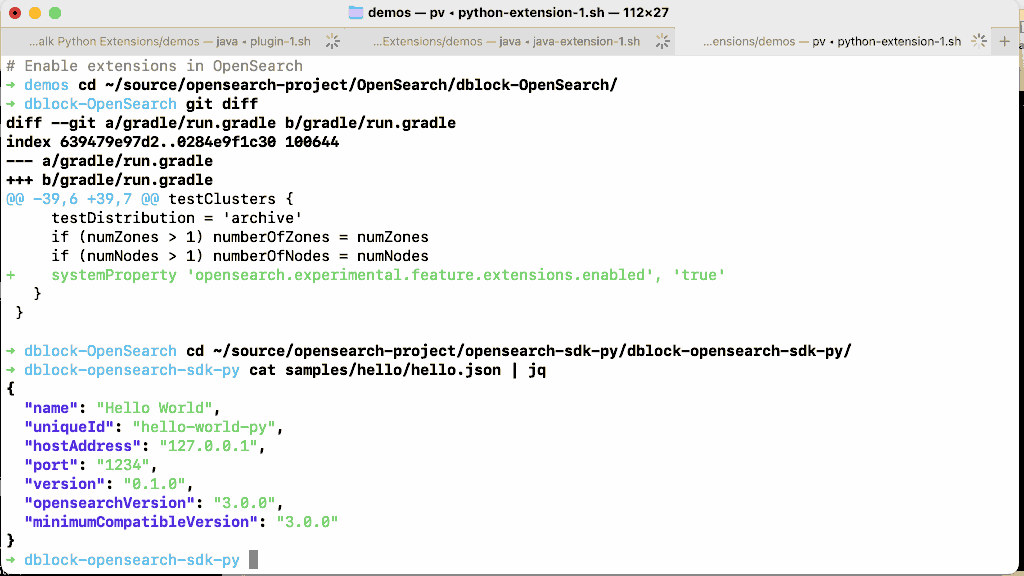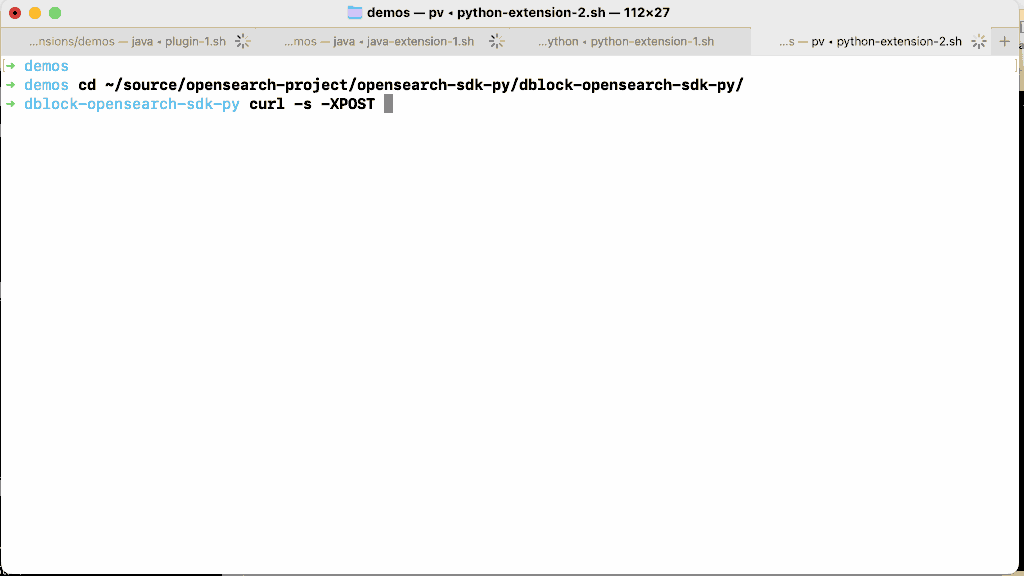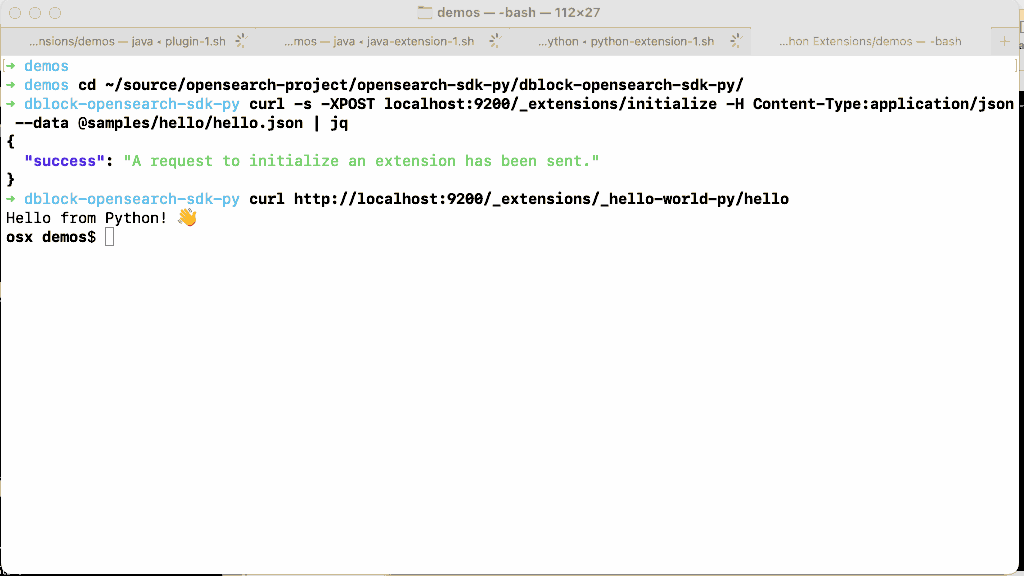
How is this even possible? What is the bridge between OpenSearch, implemented in Java, and an extension written in Python?
With most heavy lifting done by Dan Widdis of OSHI fame, we reverse-engineered, then implemented the Elasticsearch/OpenSearch transport protocol in Python, then took the extensions support for the ride. The latter was very easy because extension messages are all implemented using protobuf and you can just compile those to Python with existing tools.
In theory, to quote an Engineer from Aryn, this opens up the entire Python model zoo-space to OpenSearch, including TensorFlow or Pytorch. But it also shows how one could implement an entire OpenSearch node in another language that doesn’t suffer from, for example, GC pauses.
I hope that someone reading this blog post will build a useful extension in Python for OpenSearch. Can you make it happen?